基于深度学习的计算机视觉(CV)模型,比如图像分类,在应用上比较成熟了。
不管是ImageNet的分类模型,还是目标检测模型,都在实际应用中取得很好的效果,准确率、召回率达到生产要求。
深度学习模型虽说成熟,但数据的组织却远没那么容易。而数据的好坏,决定了最终的应用效果。
一句话,在CV实际项目中,通常会花约80%以上的时间,用来搞数据。
(一)确定数据的形式,即数据的内容是什么
对不同的业务,数据的内容要求是不同的。
比如,对自动驾驶,要有大量的交通路况数据。
对医疗影像,要有大量的医院成片数据。
对鉴黄,就要有大量的涉黄的影视和图片样本。
(二)选择合适的数据来源,即数据采集途径
数据采集是计算机视觉任务中一大难点。
对平台性公司,比如BAT这种,有天然的数据优势。他们有海量的用户,用户的数据积累在他们系统中,为AI任务提供了良好的条件。
对普通的创业型公司,数据来源是个难点。我见到很多公司是买的数据,或者联系百度、阿里等众包服务,帮他们采集数据。
一般AI项目里,数据的成本要占到整个项目成本的30%左右。
如果是通用的图像分类任务,网上有大量的开源数据集可用。比如ImageNet、COCO,这些数据可以充分利用起来,完成冷启动过程。
(三)数据的结构设计,包括分层比率
打个比方,对于鉴黄的分类模型,肯定不是扔一些色情图片进去,就可以作为样本跑起来。这里涉及到数据的分层结构。
模型一上线,就会产生如下四类数据:
- TP:真的正样本,即确实是色情图片,模型正确识别出来
- FP:假的正样本,即不是色情图片,但被模型误判为色情
- TN:真的负样本,即确实不是色情图片,模型识别正确
- FN:假的负样本,即明明是色情图片,但模型漏过了,这部分至关重要
在模型完成冷启动,上线运行后,需要进行持续的数据迭代。
所谓数据迭代就是指线上预测的数据回流回来,再由人工审核或其他模型二审,得到上述四个维度的精准数据集。我们自己的项目,就花了大量时间在人工二审上。
这四个数据集补充到训练样本里,完成新的模型训练,这叫模型迭代。
而它们的分层比率,也需要精确计算。比如模型的召回率太低,就要加大FN的比率。
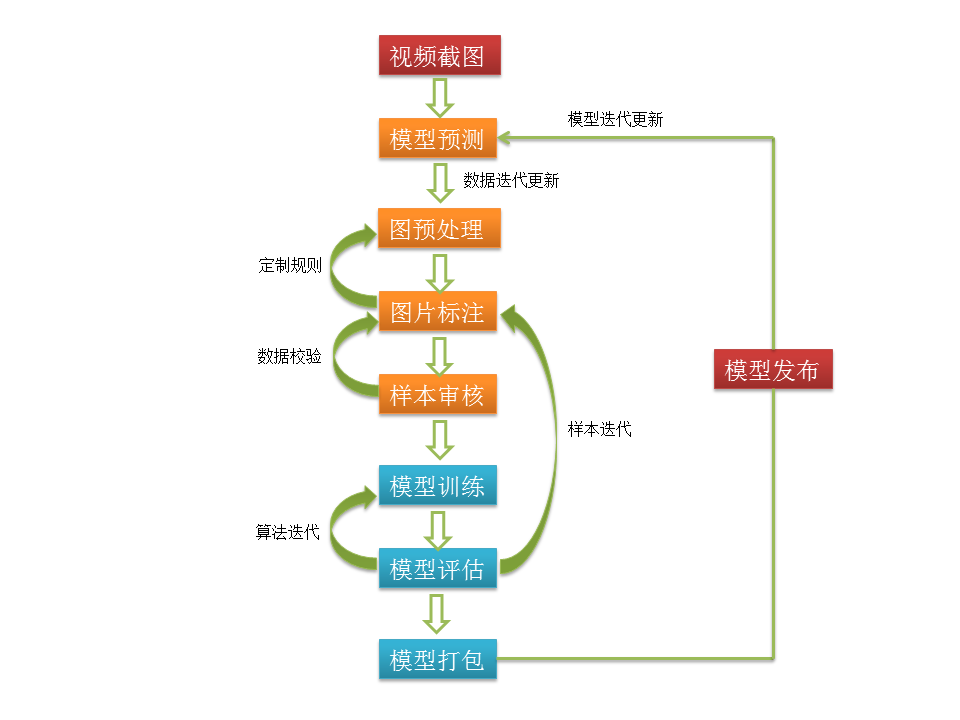
(图1:数据迭代、模型迭代)
通过这个分类模型案例,我们可以看到工程在AI项目里的作用至关重要。它保证了数据迭代、模型迭代的过程,从而让模型越来越智能。
很多AI项目落不了地,就败在工程上。
(四)数据的标注和审核
原始数据采集回来后,需要做标注。
比如,对于分类任务,就要标记图片为哪个类别;对于目标检测,就要把图片里的目标框起来,并设置标记;对于人体关键点检测,就要标明每个关键点的位置;对于语义分割,就更复杂,是像素级的标记。
不是简单标完就了事,因为每个人对标注对象的理解不一样,所以标完还要审。
可以采取多标的方式来自动审核。标完由模型过一遍,如果多份标注的计算结果一致,则说明标注正确;否则就打回重标。
这部分工作也费时费力,通常一个算法人员,对应的是一堆标注人员。
(五)数据的统计
数据的分布、数据的版本管理、数据对模型的影响,这些统计的细节工作同样重要。
在深度学习视觉领域,数据代表了一切。
只有深入了解数据、分析数据、把握数据,才可能把工作做好。
COCO视觉挑战赛,得分最高的不一定是模型最优秀的,而是对数据最了解的。

(图2:数据是保证项目成功的关键)
总结:在AI实际应用中,算法重要,数据、工程也同等重要。如果你找到了精通算法的博士,不代表项目就可以成功。在设计算法的同时,请同时把数据分析团队、工程研发团队搭建好,AI项目才真正可能落地。