人工智能行业有句老话:有多少人工,就有多少智能。
经常有人问我,这个问题能否用AI解决,那个问题能否用AI解决。
我的回答是,首先看你有多少数据,以及有多少人搞数据。
数据的重要性不言而喻,在我之前的文章有谈及。
而很多人忽略的一个事实是,搞数据的人力储备,同样不可或缺。
我们知道计算机视觉的模型训练,依赖大量的样本图片。首先要有足够的原始图片,有了图片后还要对数据进行组织和标注,这两项都是耗时巨大的工作。

先说说数据组织
一般缺乏数据的中小型公司,会采取众包、爬虫等方式获取外部数据。
而对平台型公司,自己的业务就能产生海量数据,这种是机器学习最佳实践。
但是,不意味着有数据来源,工作就轻松了。
对数据的组织、整理、分类,又是一项费时费力的工作。
再次以机器审核为例,通过模型训练,自动识别图片是否违规(比如色情、涉政)。
我们自己的业务,每天大概产生一亿张图片,这些图片都进入机器学习模型,用来做秩序审核。
模型审核的结果,包括两种可能:违规、不违规。
但是,这只是机审的结果,它可能正确或不正确,因此需要人工二审介入。
人工二审的工作点:
- 在违规图片里,审核出哪些是真的违规(TP)、哪些是误判的(FP)
- 在不违规图片里,审核出哪些是真的不违规(TN)、哪些是漏判的(FN)
工作流程如下:
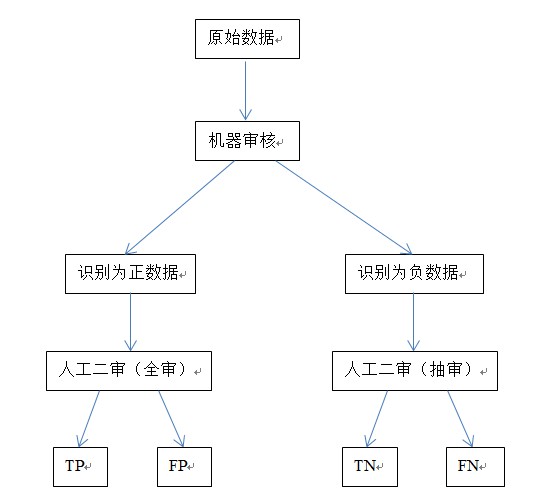
上述TP、FP、TN、FN四个成分,是我们最终需要的数据,用来产生模型训练的样本,构建合适的数据分层。
我们看到,人工二审在这个体系里至关重要,它负责结果的最终正确性。
线上每天产生一亿张原始图片,假设机审的结果,识别为正的图片为10万张,那么人工二审就要在10万张里,挑选出TP和FP。
识别为负的图片有9千多万张,自然不可能全部人审,那么就抽样。哪怕是按5%抽样,也有将近500万张图片,需要在其中挑选出TN和FN。
这是一项工作量十分巨大的工作,我们有几十号人兼着来做这个事。
再说说标注
同样是一项耗时费力的工作,还要依赖于先进的工具,比如好用的标注系统。
前面文章说过,标注规则依赖于业务的不同而不同,有的简单,大多数很复杂。
我自己试过标一项人体关键点数据,半天才标了50张,头昏脑涨的。
而线上系统每天产生数万张图片要标注,这个工作量可想而知。
标完还要审,因为每个人对标注规则的理解不一致,不太可能一次性标完就通过。
不过,标注有一些可以省力的地方,包括:
- 标的时候,用模型预标注,再由人工去核对,就快得多
- 审的时候,可以采用多标方式,标完由模型过一遍,如果多个人标的结果一致,则自动通过;如果结果差异大,则打回重标
没有轻松的数据工作
样本的数量,标注的质量,对模型的结果至关重要。而不管样本还是标注,都意味着非常巨大的工作量。在进行机器学习业务之前,先想清楚自己是否有足够的数据,以及是否有足够的人来处理数据。