谈谈AI平台化
by 司马顿 | 2018年11月9日 上午11:13
最近看了不少AI平台化的案例,包括百度的EasyDL,第四范式的AutoML,Ucloud的UAI,还有两家创业公司oneclick和偶数科技。
人工智能经过近几年突飞猛进的发展,从上层的算法,到底层的硬件,都取得了极大的突破。单纯拼算力、算法的时代已经过去。只要花点钱,就能在阿里云、腾讯云、google云上购买到想要的计算能力。而在图像识别的三大领域:分类、检测、分割,算法也基本成熟,很多模型可以开箱即用。
AI今后的发展,就是一个工具集,不管分类也好、回归也好,就是工具集里的一个工具。用户随手拿起一个工具,稍加锻造(小数据集训练),就能真正为我所用、得心应手。
在此发展过程中,很多公司看到了机会,推动AI平台化进展。所谓AI平台化,就是AI与环境的一个整合过程,面向用户提供高度集成的AI生产和运行环境,隐藏了算法、算力、存储、网络细节,使得AI更容易使用。
AI平台化实现起来,很有挑战,涉及的面非常广。借用其他公司的一张图来说明:
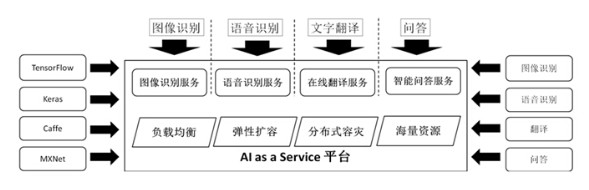
底层的那一套资源管理机制,负载均衡、弹性扩容、容灾、资源分配等,实际是个私有云环境。底层要负责好三块的资源供给:算力、存储、网络。
在算力调度上,目前业内做法都是容器化,通过docker生成任务实例,以支持机器学习框架(tensorflow等)的分布式训练。
在存储机制上,HDFS、Ceph都是比较成熟的解决方案,可以使用HDFS的专用客户端来完成存储读写,也可以使用Ceph的分布式块存储来进行集成。
在网络上,大容量、高吞吐量的网络(25gbps)是必选,因为在图像类训练任务里,网络吞吐量很大。如果要保证隐私和资源隔离,还要实现SDN(虚拟私有网络)。
在我们自己的解决方案里,使用K8S管理静态资源,比如HDFS、Hadoop、Zookeeper、web service,使用Yarn来管理docker容器,比如生成新的任务实例。算力分配通过docker进行,包括GPU、CPU分配。共享存储使用HDFS,网络带宽是25gbps。由于任务实例是docker,因此里面可以集成任何机器学习框架,包括tensorflow、caffe等。
这个图里描述的只是训练部分。实际上,一个完整的机器学习任务,包括数据处理 -> 模型训练 -> 模型部署的过程。
数据处理工作十分复杂,例如结构化数据的特征工程(数据清洗、分析、特征转换),图片数据的标注等。它们都需要相应的系统支持,比如结构化数据存储和计算,一般用到Hadoop、Spark这类系统,规模十分庞大。而非结构化数据(图片、视频)的存储和计算,也需要用到很大的集群。
模型部署到线上进行预测,或者发布到移动端SDK,也涉及到复杂的工程工作。
部署到线上后,要考虑后续的监控、扩容、容灾问题,而且机器学习任务的计算量很大,通常调度的机器也就更多。我们做的一项AI业务,在线上部署了100多台物理服务器在跑,对这么多硬件进行管理和调度,本身就不简单。现在很多AI业务部署是基于容器,一方面轻量化了部署过程,另一方面也不可避免的面对容器自身管理的复杂性。
移动端SDK面临的压力主要是性能优化。iOS还好,可以通过Apple自己的开发框架来调度手机的GPU,但Android阵营就复杂了,各种机型和GPU千差万别,如何适配不同手机的GPU是个大难题。另外,模型自身还要做压缩、裁剪、量化,以提升移动端计算性能。在AI平台里,一个好的移动端推理框架集成进来,会给平台大大加分。

上述描述的是AI平台的资源环境管理工作,AI平台对计算、存储、网络等硬件环境进行整合和集成,更好的适应AI开发和运行任务。而好的AI平台,还要对算法进行包装和抽象,以最大的便利性,支撑用户的模型开发任务。
这方面做得最好的是Google的AutoML,只要上传训练数据、指定任务目标,AutoML就帮你自动设计神经网络结构、自动训练和评估模型效果,用户不用关注底层的算法和工程实现,平台帮你把一切都做好了。百度的easyDL基于迁移学习,也是类似效果。
总结起来,一个好的AI平台,解决的不止是底层的工程实现问题,还解决了上层的算法封装问题,用户甚至可以零学习成本使用AI平台进行业务开发。我相信这样的平台会越来越多,AI开发的门槛也会越来越低,这对AI的普及来说,是个好事。
当然,这不意味着算法人员就没有用途了。专业的算法人员,可以投入到更高级的研究方向上,比如神经架构搜索、强化学习、神经芯片等,这些基础技术,会让AI更容易普及,更好的造福社会。将来AI在社会生活的各个领域,推动生产进步,改进生活质量,就充分体现了科研人员的价值。
Source URL: https://smart.postno.de/archives/661