我经常使用ipip.net的免费API查IP,这个网站挺好用的。
一个简单的命令如下:
$ curl -s http://freeapi.ipip.net/202.96.128.68
[“中国”,”广东”,”广州”,””,”电信”]
上述查询202.96.128.68这个IP,得到的结果是广东电信。
但最近登录一台服务器,发现上述查询的返回结果乱码。
我看了下curl返回的header:
$ curl –head http://freeapi.ipip.net/202.96.128.68
HTTP/1.1 200 OK
Date: Tue, 24 Jul 2018 08:04:14 GMT
Content-Type: application/json;charset=utf-8
…
ipip.net网站的响应编码是UTF-8。而我的终端环境也是UTF-8:
$ locale
LANG=en_US.UTF-8
LANGUAGE=
…
都是UTF-8为什么还乱码呢?有点郁闷。
于是祭起google神器,得到一个解决方案:
$ curl -s http://freeapi.ipip.net/202.96.128.68 |iconv -f utf8 -t gb2312
运行上述命令,返回结果是正确的。
iconv的意思是,将输入为UTF-8的字符串,转换为GB2312进行输出。
但我的终端环境已经是UTF-8呀,为什么还要转换成GB2312?
百思不得其解。
我是在工作机Windows,通过SecureCRT连接到远程Linux服务器的。
无意中打开SecureCRT的配置进行检查,发现它的编码方式设置为默认:
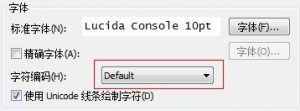
这可能是问题所在。于是把这里修改为UTF-8:
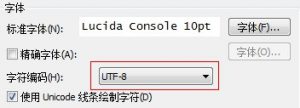
重新登录服务器,运行本文的第一句命令,问题解决,不乱码了。
结论是,对于Linux服务器,终端客户端的编码约定,会覆盖服务器的编码设置。两者设置成一致,才能避免各种乱码问题。